
딥러닝 1주차 - OT & Numpy Tutorial
dl
9월 16일, 첫 세미나가 성공적으로 끝난 후, 각 커리큘럼들은 서로 모여서 OT를 진행했습니다!
떨리고 설레던 그 첫 시간을 톺아보도록 하죠!
Agenda
- 딥러닝 커리큘럼을 이끌어갈 리드와 코어
- 딥러닝 커리큘럼 소개
- 딥러닝 커리큘럼 일정
- 딥러닝 커리큘럼 진행 방식
- Numpy Tutorial
1. 딥러닝 커리큘럼을 이끌어갈 리드와 코어
세미나 시간에는 자신에 대해서 짧게 언급했어야 했죠 😥
리드와 코어가 어떤 사람인지, “딥러닝”에 대해 얼마나 공부했는지에 대해서 소개하고자 마련했습니다! :)
2. 딥러닝 커리큘럼 소개
사실 GDSC Seoultech 1의 ML/Data는 다양한 머신러닝의 기법들에 대해서 익히고, 캐글 필사를 하며 머신러닝에 대해서 익혔습니다.
하지만! 우리가 배운 머신러닝 기법들을 솔루션 챌린지에서 바로 적용해보기가 어렵다! 라는 결론에 이르러,
이번 GDSC Seoultech 2는 Deep Learning으로 방향성을 잡았습니다.
많은 분들이 아시다시피, 데이터의 세계는, 그리고 우리가 함께 공부할 딥러닝의 세계는 정말 무궁무진합니다.
우리가 배우는 것은 걸음마라고 할 수 있을 정도에요.
그래서 딥러닝의 모든 것을 배우는 것이 아닌 딥러닝의 기초 부터 잘 다져서,
간단한 모델이라도 스스로 구현할 수 있는 것을 목표로 정했습니다!
우리가 12월까지 배운 걸 발판 삼아 여러분이 딥러닝의 매력에 푹 빠졌으면 좋겠다는 게 … 저의 아주 작은 바람이랄까요 ㅎㅎ… 😏
3. 딥러닝 커리큘럼 일정
딥러닝 커리큘럼은 다음의 순서로 진행할 예정입니다.
- 1주차: OT + Numpy 소개
- 2주차: 데이터의 기본과 Tensor
- 3주차: 딥러닝의 과정 with MLP
- 4주차: 가중치와 과대적합
- 5주차: 회귀모델을 알아보자.
- 6주차: 분류모델도 알아보자.
- 7주차: CNN1
- 8주차: CNN2
- 9주차: NLP1
- 10주차: NLP2
- 11주차: NLP3
- 12주차: 최신 모델 소개 & 딥러닝 어워드
한 학기동안 열심히 달려보아요 🕺
4. 딥러닝 커리큘럼 진행 방식
딥러닝 커리큘럼은 수업 형식으로 진행됩니다.
매주 퀴즈와 이전 주차를 복습하면서 커리큘럼을 시작하고, 이론 공부를 약 30분 간 진행한 후 실습 20분으로 마무리 합니다.
기본적인 뼈대는 이런 식으로 가져가되, 여러분에게 더 내용을 잘 전달하기 위해 시간이 조금씩 변동될 수 있다는 점 이해해주세요 :) 🙃
매 수업이 끝나고 과제가 주어집니다.
과제에 대한 여러분의 부담을 줄이기 위해, 각자 다 다른 분야를 공부해서 팀블로그에 정리하는 것을 생각하고 있어요!
이번 포스팅에도 여러분의 완벽한 과제가 게시될 예정입니다 😎
5. Numpy Tutorial
첫 시간인 만큼 짤막한 Numpy Tutorial을 준비해보았는데요,
우리가 사용하는 Pytorch가 Numpy와 굉장히 유사하니,
둘 중 하나만 아주 깊이 파도 나머지 한 개는 절반은 먹고 들어간다는 게 저의 의견 ,,, 🫠 입니다!
그리고 중간 중간 딥러닝 분들의 완🌟벽🌟한 과제도 나올테니,
눈 크게 뜨고 읽어주세요 👀
1) 배열 생성
x = np.array()
Numpy는 ndarray 타입의 배열을 주로 가지는데요,
이러한 ndarray는 위와 같은 방법을 통해 만들어집니다.
과제 1 [준석]: Numpy array와 Python List의 차이는?
1) 연산
python list는 덧셈 시 항목을 이어 붙이는 concatenate를 수행합니다.
또한, 리스트 간의 다른 연산은 허용하지 않습니다.
곱셈은 자연수 곱셈은 가능하며, 원소 복사를 의미합니다.
반면, numpy array에서는 덧셈 시 각 요소별 덧셈을 수행합니다.
또한 나머지 연산에서도 마찬가지로 numpy array끼리의 연산이 가능합니다.
a = [1,2,3,4]
b = [5,6,7,8]
print(a+b) # 덧셈 시 리스트끼리 연결됨
print(a*2) # 리스트에 상수 곱셈 시 반복됨
[1, 2, 3, 4, 5, 6, 7, 8]
[1, 2, 3, 4, 1, 2, 3, 4]
''' 리스트간의 다른 연산 허용 X '''
print(a-b) # 리스트간의 뺄셈 불가
print(a*b) # 리스트간의 곱셈 불가
print(a/b) # 리스트간의 나누기 불가
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_36224\1204855391.py in <module>
1 ''' 리스트간의 다른 연산 허용 X'''
----> 2 print(a-b) # 리스트간의 뺄셈 불가
3 print(a*b) # 리스트간의 곱셈 불가
4 print(a/b) # 리스트간의 나누기 불가
TypeError: unsupported operand type(s) for -: 'list' and 'list'
''' numpy array의 경우'''
npa = np.array(a)
npb = np.array(b)
print(npb*2) # array에 상수 곱셈 시 리스트와 달리 반복되지 않고 각 요소들에 곱해짐
# numpy array 끼리의 사칙연산 전부 가능
print(npa+npb)
print(npa-npb)
print(npa*npb)
print(npa/npb)
[10 12 14 16]
[ 6 8 10 12]
[-4 -4 -4 -4]
[ 5 12 21 32]
[0.2 0.33333333 0.42857143 0.5 ]
import numpy as np
npa = np.array(a)
npb = np.array(b)
print(npa+npb)
[ 6 8 10 12]
보다시피 넘파이 어레이에서는 실제 값이 연산될 결과값을 반환합니다.
2) 성능차이
Numpy array가 리스트보다 훨씬 빠릅니다.
또, 파이썬 리스트는 다양한 종류의 타입을 저장할 수 있습니다. 하지만, 리스트와 달리, Numpy array는 동일한 타입의 데이터만 저장할 수 있습니다. 만약, 넘파이의 array에 다른 타입이 입력된다면, 전부 문자열로 변경합니다.
a = [1,2,3,'a','b'] # 1,2,3은 숫자형, 'a','b'는 string
b = np.array(a) # '1','2','3','a','b' 전부 문자열로 변경
이렇게 동일한 자료형으로만 데이터를 저장하면, 각각의 데이터 항목에 필요한 저장공간이 일정하게 할당됩니다.
따라서 몇 번째 위치에 있는 항목이든 그 순서만 안다면 바로 접근할 수 있기 때문에 훨씬 적은 메모리로 빠르게 데이터를 다룰 수 있게 됩니다.
2) N차원 배열
딥러닝은 그 수준의 깊이가 깊어질수록 고차원의 데이터를 다루는데요,
차원에 따라 부르는 이름이 다릅니다!
- 1차원 배열: Vector
- 2차원 배열: Matrix
- 3차원 이상의 배열: Tensor
우리가 쓸 대부분의 데이터는 Tensor 형태입니다.
3) 2차원 배열의 연산과 브로드캐스트
여기서부터는 모두 과제로 대체하였는데요, 그럼 한 번 함께 볼까요?
과제 2 [혁]: 2차원 배열의 연산은 어떻게 될까?
2차원 배열의 연산 같은 경우는 아래의 코드처럼 동일한 위치에 있는 요소를 사칙연산 하는 것입니다. 사칙연산 기호를 사용하면 됩니다.
import numpy as np
arr_1 = np.array([[1, 2],[3, 4]])
arr_2 = np.array([[2, 3],[5, 6]])
arr_plus = arr_1 + arr_2
arr_minus = arr_1 - arr_2
arr_mul = arr_1 * arr_2
arr_div = arr_1 / arr_2
print(arr_plus)
print(arr_minus)
print(arr_mul)
print(arr_div)
result) [[ 3 5] [ 8 10]]
[[-1 -1] [-2 -2]]
[[ 2 6] [15 24]]
[[0.5 0.66666667]
[0.6 0.66666667]]
위처럼 동일한 위치의 요소에 사칙연산을 진행하는 것이기 때문에
각 배열의 행,열 개수가 다르게 되면 아래와 같이 에러가 발생합니다.
import numpy as np
arr_1 = np.array([[1, 2],[3, 4],[1,2]])
arr_2 = np.array([[2, 3],[5, 6]])
arr_plus = arr_1 + arr_2
print(arr_plus)
result) ValueError: operands could not be broadcast together with shapes (3,2) (2,2)
과제 3 [정준]: Python-Numpy에만 있는 Broadcasting이란?
1주차 DL과제 - (3)
Broadcasting이란?
numpy가 연산 중에 다른 모양(shapes)의 배열을 처리하는 방법, 즉 다차원 배열에서 shape가 다른 배열끼리의 연산이 가능하게 하는 기능입니다. 단 이 기능은 배열의 모양이 특정 조건을 충족할 때 작동합니다.
일반적으로 모양이 다른 배열끼리는 연산이 불가능하지만,
어떤 조건을 만족한다면 부족한 부분(더 작은 차원)의 값이 확장되는 형태로 연산을 수행할 수 있게 됩니다.
즉, 배열을 계산이 가능한 형태가 되도록 임의로 변형(차원이 확장되는 형태로 변형)이 이루어져서 broadcasting이라고 일컫게 되었습니다.
예를 들어,
a = np.array([[1,2],[3,4]])
b = np.array([10, 20])
a * b
array([[10, 40], [30, 80]])
결과는 위처럼 b라는 1차원 배열이 2차원으로 확장되어서 곱해집니다.
정리해보면, 브로드캐스팅이 적용되는 조건은 다음과 같습니다.
- 이어지는 두 축에 대해 축의 길이가 일치할 때
- 둘 중 하나의 축의 길이가 1일 때
이 조건이 충족되지 않으면, ValueError: operands could not be broadcast together라는 에러가 발생하면서 배열이 서로 호환되지 않는 shape임을 나타냅니다.
참고로, 배열은 반드시 같은 차원의 수를 가질 필요는 없습니다. (단 이 경우는 무조건 하나의 축은 1이어야 함을 전제로 합니다.)
둘 중 하나의 차원이 1차원, 이 1차원이 확장되어서 다른 배열의 차원과 호환이 가능해집니다.
실제로 브로드캐스팅의 예제는 아래와 같습니다.
import numpy as np
arr1 = np.array([[0, 0, 0],
[1, 1, 1],
[2, 2, 2]])
arr2 = np.array([5, 6, 7])
print(arr1 + arr2)
[[5 6 7]
[6 7 8]
[7 8 9]]
import numpy as np
arr3 = np.array([1, 1, 1])
arr4 = np.array([[0],
[1],
[2]])
print(np.add(arr3, arr4))
[[1 1 1]
[2 2 2]
[3 3 3]]
import numpy as np
arr = np.arange(1, 4)
# [1 2 3]
x = 2
print(arr * x)
# [2 4 6]
배열과 스칼라 연산에도 브로드캐스팅이 적용됩니다.
import numpy as np
a = np.array([[ 0.0, 0.0, 0.0],
[10.0, 10.0, 10.0],
[20.0, 20.0, 20.0],
[30.0, 30.0, 30.0]])
b = np.array([1.0, 2.0, 3.0])
print(a + b)
[[ 1. 2. 3.]
[11. 12. 13.]
[21. 22. 23.]
[31. 32. 33.]]
과제 4 [재영]: 배열 초기화 방법 3가지 정리하기
numpy에서 배열을 초기화할 수 있는 방법은 아래와 같습니다.
- np.arange()
- np.ones()
- np.zeros()
이에 대해 하나하나 살펴보도록 합시다.
1. np.arrange()
numpy 공식 문서에서 np.arange 함수의 설명을 살펴보면 아래와 같습니다.

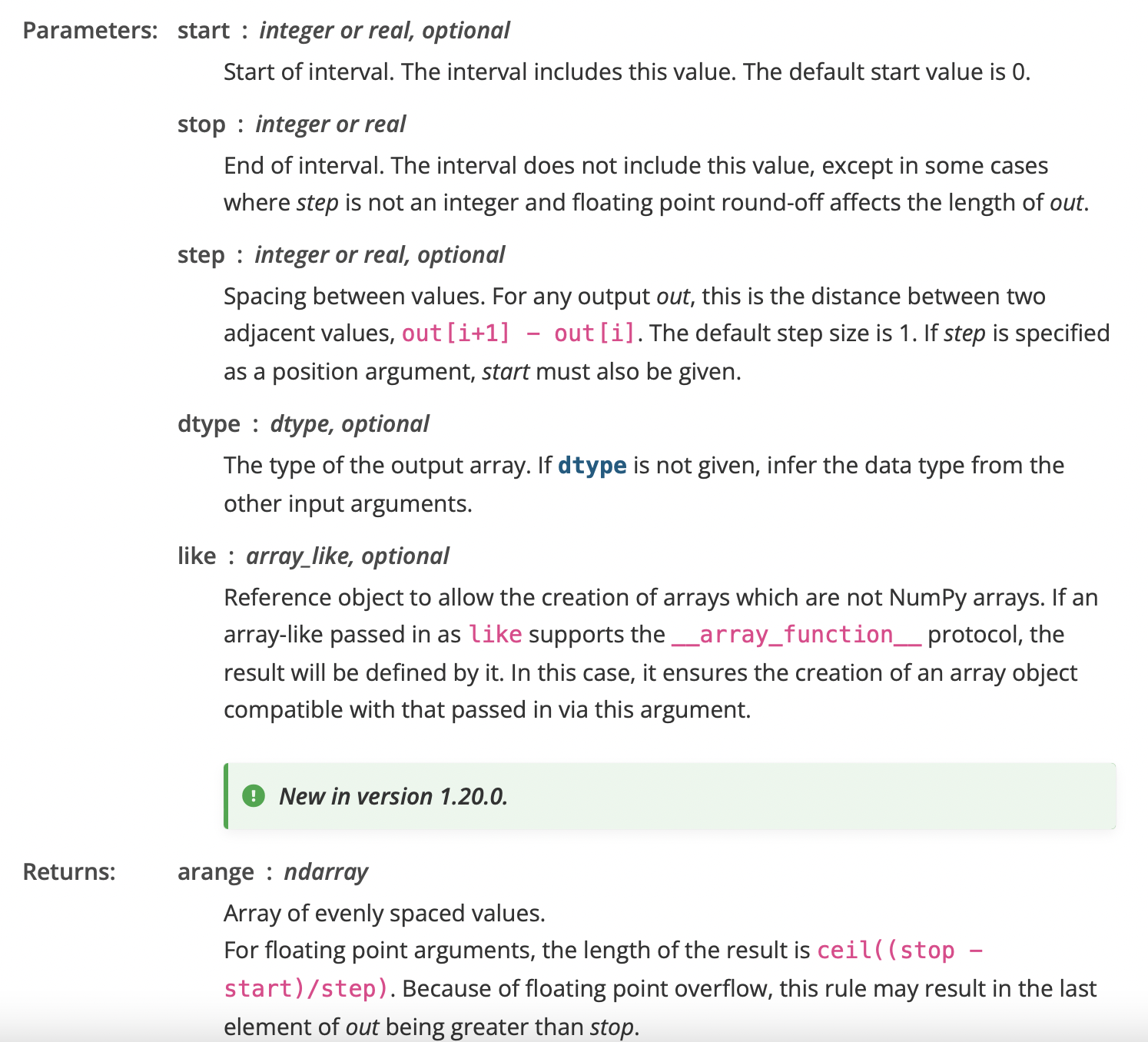
위에서 볼 수 있듯이 주어진 간격 내에서 균일한 간격의 값을 반환하는 역할을 하는 함수입니다.
즉, 말 그대로 정해진 값의 구간 및 step을 부여하여 그에 맞는 숫자를 배열하는 초기화를 수행하게 됩니다. 기본적으로 start = 0, step = 1이 기본적으로 정의되어 있는 파라미터 값이며, 이는 필요에 따라 수정할 수 있습니다.
2. np.ones()
np.ones 함수는 numpy 배열을 생성할 때, 모든 원소를 1로 초기화해주는 함수입니다. 이와 관련하여 numpy 공식 문서를 살펴보면 아래와 같습니다.

위 공식 문서에 작성된 내용대로 np.ones 함수를 활용하면 주어진 shape과 type의 새로운 배열을 만들어 1로 채워 반환하는 역할을 하게 됩니다.
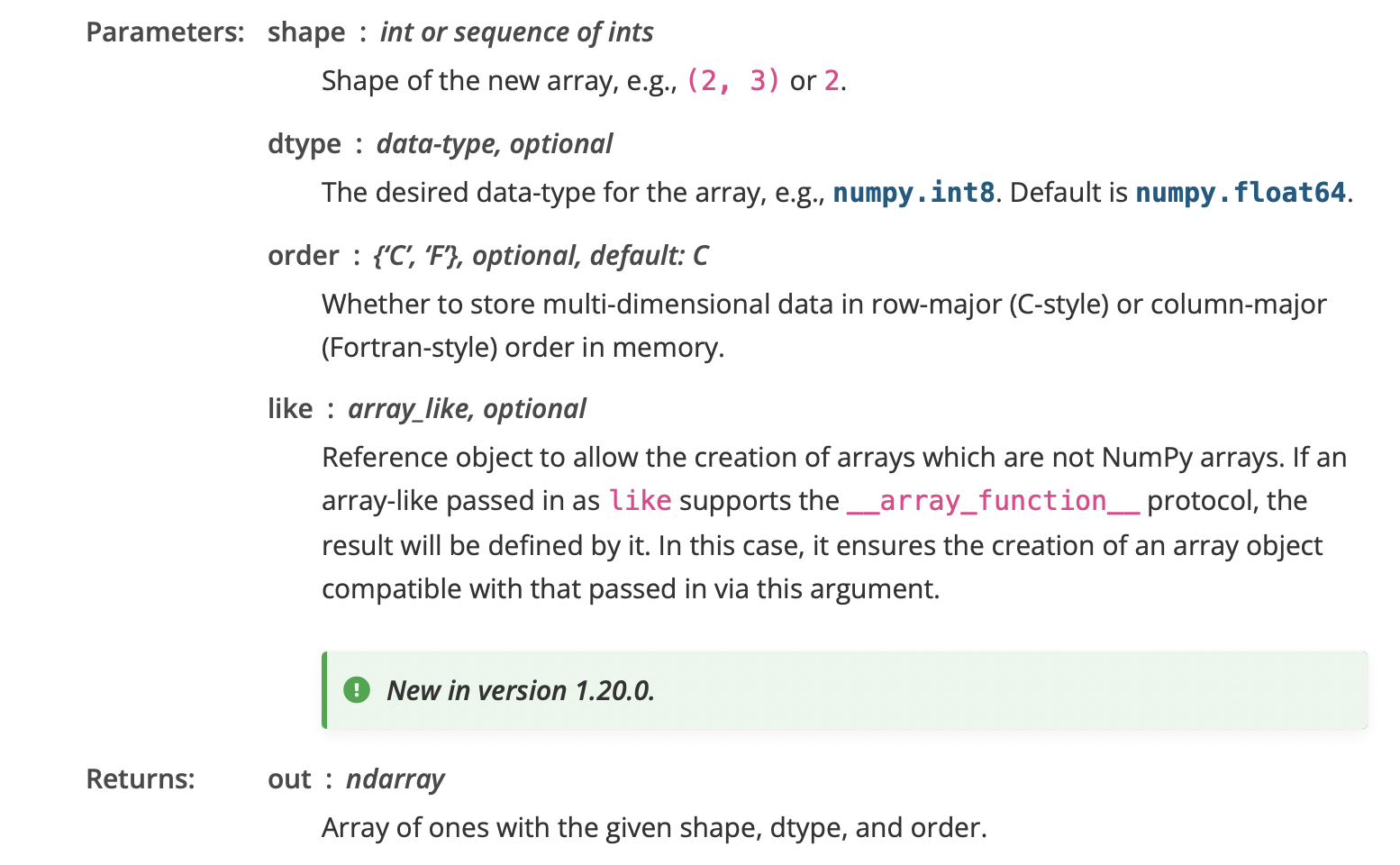
3. np.zeros()
위에 살펴보았던 np.ones 함수가 생성된 배열을 1로 채워 초기화하는 함수였다면, np.zeros 함수는 이름 그대로 생성된 배열을 모두 0으로 채우는 함수라고 할 수 있습니다.
그렇기에 이 함수는 이미지 처리 등에서 padding(이미지 경계 축소를 방지하기 위하여 경계선을 지정하는 방법)을 진행하기 위하여 자주 사용되는 함수입니다.
이와 관련하여 numpy 공식 문서의 해설을 보면 아래와 같습니다.

위 공식 문서에 작성된대로 shape과 type을 입력하여 그에 대한 배열을 생성한 뒤, 모두 0으로 채워넣는 역할을 하게 됩니다.

과제 5 [연수]: 베열 모양 변경 방법 알아보기
np.reshape(원본 numpy, shape) 는 원본 numpy를 shape 차원으로 바꾼 numpy를 반환합니다.
이는 원본 numpy.reshape(shape) 로 써도 동일한 결과값을 가집니다.
# numpy reshape
import numpy as np
a = np.array([x for x in range(1,11)])
a_25 = np.reshape(a, (2,5))
a_52 = a.reshape((5,2))
print("shape " + str(a_25.shape))
print(a_25)
print()
print("shape " + str(a_52.shape))
print(a_52)
shape (2, 5)
[[ 1 2 3 4 5]
[ 6 7 8 9 10]]
shape (5, 2)
[[ 1 2]
[ 3 4]
[ 5 6]
[ 7 8]
[ 9 10]]
하지만 만약 원소 개수가 맞지 않으면 어떻게 될까요?
만약 원본 numpy 배열은 10개일 때, 이를 15개의 원소를 가지는 배열로 바꾸면 어떻게 될까요?
a_53 = np.reshape(a, (5,3))
print(a_53)
ValueError: cannot reshape array of size 10 into shape (5,3)
이와 같은 오류가 발생합니다.
그래서 꼭 원소 개수를 맞춰줘야합니다.
그럼 다음으로 만약 dimmension을 지정해주기가 번거로운 상황이라면 어떻게 할까요?
shape에 -1을 인자로 넣어주면 됩니다!
-1은 원소의 개수에 맞게 조정이 됩니다. 대신! 기준이 되는 숫자는 약수를 넣어줘야 합니다.
a_5n = np.reshape(a, (5,-1))
print("shape " + str(a_5n.shape))
print(a_5n)
shape (5, 2)
[[ 1 2]
[ 3 4]
[ 5 6]
[ 7 8]
[ 9 10]]
다음은 reshape와 view입니다.
## torch reshape view
import torch
a = torch.arange(10).reshape(5,2)
여기서 이와 같이 0부터 1까지의 ndarray를 만들어주고, 이를 (5,2)의 shape을 가지는 배열로 reshape 해주겠습니다.
a.transpose_(0,1)
a = a.view(10,1)
그 후에 a를 transpose 해주고, 이를 view로 shape을 바꾸면 어떻게 될까요?
RuntimeError: view size is not compatible with input tensor’s size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(…) instead.
이와 같은 RuntimeError가 발생합니다. 그 이유는 contiguous의 여부가 바뀌었기 때문이죠.
자세한 건 이 블로그를 참고해주세요.
이와 같이 바꾸고자 하는 배열의 속성을 정확히 모를 때에는 reshape를 사용해주면 됩니다.
위의 경우를 reshape로 다시 써보겠습니다.
a = a.reshape(10,1)
a
tensor([[0], [2], [4], [6], [8], [1], [3], [5], [7], [9]])
b = torch.arange(10).view(10,1)
b
### contiguous가 True 인 상태에서는 view로 shape 변경이 가능하다.
tensor([[0], [1], [2], [3], [4], [5], [6], [7], [8], [9]])
여기까지가 딥러닝 커리큘럼 분들의 과제입니다!
정말 훌륭하지 않나요 ?!
여러분의 과제를 보며 저 또한 복습이 되면서 개념들이 명확해진 것 같아요!
첫 과제부터 이렇게 완벽하게 해주시다니 짱입니다 👍
여기까지 딥러닝 커리큘럼 1주차 내용이었는데요,
앞으로가 더욱더 기대되네요!
앞으로도 DL 커리큘럼의 팀블로그, 기대해주세요 🙌
