
3주차 지도학습 첫번째 시간
ml😃 지난주 과제
:q
- 추석 연휴로 인해 강의 자료로 matplotlib과 seaborn을 학습
- kaggle - Simple Matplotlib & Visualization Tips 필사
이번 주부터는 본격적인 기계학습, 머신러닝을 배워볼 예정입니다. 머신러닝은 크게 지도 학습과 비지도 학습으로 나뉩니다.
⭐머신러닝
1. 지도학습
2. 비지도학습
우리는 이 중에서도 지도학습을 먼저 배워볼 예정입니다.
이 지도학습 중에서도 일반화부터 나이브 베이즈 분류기까지 다룰 것입니다.
일반화
generalization
지도학습에서 사용자는 알고리즘에 입력과 기대되는 출력을 제공합니다. 알고리즘은 새로 주어진 입력에서 원하는 출력을 만드는 방법을 찾습니다. 이렇게 학습된 알고리즘이 사람의 도움 없이도 새로운 입력이 주어지면 적절한 출력을 만들 수 있습니다.
알고리즘을 학습시키는 데 사용되는 데이터세트를 훈련세트, 모델이 새로운 데이터에 얼마나 잘 적용될 수 있을지 평가하는 데 사용하는 데이터 세트를 테스트세트 라고 합니다.
만약 모델이 처음 보는 데이터에 대해 정확하게 예측할 수 있으면, 이를 훈련 세트에서 테스트 세트로 일반화되었다고 합니다.
- 훈련 세트 : 알고리즘을 학습시키는 데 사용하는 데이터 세트
- 테스트 세트 : 모델이 새로운 데이터에 얼마나 잘 적용될 수 있을지 평가하는데 사용하는 데이터 세트
보통 훈련 세트와 테스트 세트가 비슷하다면 모델이 테스트 세트를 잘 분류할 것이라고 기대할 수 있습니다.
하지만 모델이 훈련 세트의 각 샘플에 너무 가깝게 맞춰져서 새로운 데이터에 일반화되어버린 경우도 있습니다. 이를 과대적합, overfittig이라고 합니다. 반대로 모델이 데이터의 다양성을 잡아내지 못해 너무 간단한 모델이 선택되는 것을 과소적합 이라고 합니다.
- 과대 적합 : 모델이 훈련 세트의 각 샘플에 너무 가깝게 맞춰져서 새로운 데이터에 일반화되어버린 경우
- 과소 적합 : 모델이 데이터의 다양성을 잡아내지 못해 너무 간단한 모델이 선택되는 경우
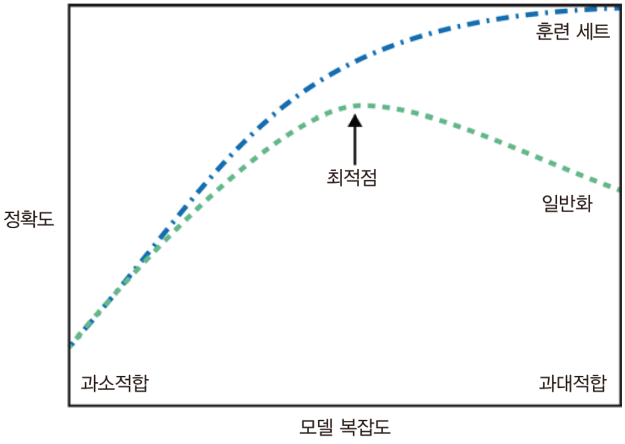
다시 한 번 정리하면 과대적합이 발생하면 훈련 세트에 대한 정확도는 높지만 테스트세트에 대한 정확도는 떨어지고,
과소적합이 발생하면 훈련 세트, 테스트 세트 모두 정확도가 낮습니다.
우리가 찾으려는 모델은 일반화 성능이 최대가 되는 최적점에 있는 모델입니다.
데이터셋에 다양한 데이터 포인트가 많을수록 우리는 과대적합 없이 더 복잡한 모델을 만들 수 있습니다.
큰 데이터셋은 더 복잡한 모델을 만들 수 있게 해주지만 같은 데이터 포인트가 중복되거나 매우 비슷한 데이터를 모으는 것은 도움이 되지 않습니다.
우리는 정확한 예측값을 위해 다양한 데이터를 더 많이 수집해서 적절하게 더 복잡한 모델을 만들어야 합니다.
k-최근접 이웃 분류
k-최근접 이웃 알고리즘은 훈련 데이터셋을 그냥 저장함으로써 모델을 만들고, 새로운 데이터 포인트에 대해 예측할 땐 가장 가까운 훈련 데이터 포인트, 즉 ‘최근접 이웃’을 찾아서 예측에 사용합니다.
아래 그림은 이웃의 수를 1로 설정한 건데, 각 데이터 포인트(별표모양)에서 가장 가까운 훈련 데이터 포인트의 레이블로 지정하여 분류하게 됩니다.
 이처럼 하나의 이웃이 아니라 k개의 최근접 이웃을 선택할 수도 있습니다. 이때는 이웃이 더 많은 클래스를 레이블로 지정합니다.
이처럼 하나의 이웃이 아니라 k개의 최근접 이웃을 선택할 수도 있습니다. 이때는 이웃이 더 많은 클래스를 레이블로 지정합니다.
아래 그림을 보시면 맨왼쪽 위의 데이터 포인트는 이웃을 하나만 사용했을 때와 예측이 달라진 것을 알 수 있습니다.

아래는 scikit-learn에서 k-최근접 이웃을 적용하는 코드입니다. 이 분류 방법을 통해 각 세트에서 테스트 점수를 출력해보는 코드를 작성해보겠습니다.
✏️ scikit-learn에서의 k-최근접 이웃
from sklearn_model_selection import train_test_split
X, y = mglearn.datasets.make_forge()
X_train, X_test, y_train, y_test = train_set_split(X, y, radom_state=0)
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(X_train, y_train)
print("테스트 세트 예측: ", clf.predict(X_test))
print("테스트 세트 정확도: {":.2f"}".format(clf.score(X_test, y_test)))

테스트 포인트 예측을 xy평면에, 그리고 각 데이터가 속한 클래스에 따라 평면에 색을 칠하면
알고리즘이 클래스 0과 클래스 1로 지정한 영역으로 나뉘는 결정 경계를 볼 수 있습니다.
그림을 보면 이웃을 하나 선택했을 때는 결정 경계가 훈련 데이터에 가깝게 나타나고 이웃을 늘릴수록 결정 경계가 부드러워집니다.
다시 말해 이웃을 적게 사용하면 모델의 복잡도가 높아지고, 이웃을 많이 사용하면 모델의 복잡도가 낮아지게 됩니다.
참고로 k값은 짝수면 2:2 이렇게 나눠질 수 있기 때문에 홀수가 좋습니다.
이러한 k-최근접 이웃 알고리즘은 회귀 분석에도 쓰입니다. 분류에서처럼 회귀 분석에서도 이웃을 둘 이상 사용할 수 있습니다. 세 개의 테스트 데이터에 대해 이웃이 하나인 분류에서는 이웃의 레이블 개수를 확인해서 다수결로 정했었는데, 회귀에서는 이웃들의 평균을 계산한다는 점에서 차이가 있습니다.
k-최근접 이웃의 특징
- 매개변수가 데이터 포인트 사이의 거리를 재는 방법과 이웃의 수입니다. 여기서 거리는 유클리디안 거리 방식을 사용합니다.
- 이해하기가 매우 쉽습니다. 많은 조정 없이 좋은 성능을 발휘하며, 매우 빠르게 모델을 만들 수 있습니다.
- 훈련 세트가 매우 크면 예측이 느려집니다. 많은 특성을 가졌거나 특성 값이 대부분 0인, 즉 희소한 데이터셋에서는 잘 작동하지 않습니다.
회귀의 선형모델
선형 모델은 입력 특성에 대한 선형 함수를 만들어 예측을 수행합니다. 회귀의 선형 모델의 일반화된 예측 함수는 아래와 같습니다.
ŷ = w[0] × x[0] + w[1] × x[1] + … + w[p] × x[p] + b
이 식에서 x는 하나의 데이터 포인터에 대한 특성을 나타내며 w는 가중치, b는 편향으로 모델이 학습할 파라미터입니다.
그리고 y hat은 모델이 만들어낸 예측값인데, 각 입력 특성 x에 대한 가중치 w를 곱해서 더한 가중치 합입니다.
선형 회귀 _ 최소제곱법

회귀용 알고리즘인 선형 회귀 또는 최소제곱법은 예측값과 훈련 세트에 있는 타깃 𝑦 사이의 평균제곱오차를 최소화하는 파라미터 𝑤와 𝑏를 찾습니다.
평균제곱오차는 예측값(𝑦𝑖)과 타깃값(𝑦 ̂𝑖)의 차이를 제곱하여 더한 후에 샘플의 개수(𝑛)로 나눈 것입니다.
평균제곱오차는 손실 함수(loss function)로 쓰이며 값이 작을수록 모델의 성능이 좋습니다.
타깃값이 예측값보다 커서 괄호 안의 값이 음수가 되는 경우도 있기 때문에 차를 제곱하여 평균을 구합니다.
리지 회귀
Ridge Regression
1. 리지회귀란?
리지 회귀는 회귀 선형 모델입니다. 선형 모델이기 때문에 예측 함수를 사용합니다. 리지 회귀가 선형 회귀와 구분되는 점 중 가장 큰 것은 바로 데이터 예측과 동시에 가중치의 절댓값을 가능한 한 작게 만드는 것입니다.
가중치의 모든 원소가 0에 가깝게 되길 원하는 즉, 기울기를 작게 만들려고 노력합니다.
이러한 것을 바로 규제라고 합니다. 과대적합인 overfittig을 막기 위한 방법입니다. 규제의 종류에는 L1과 L2가 있는데 리지 회귀의 경우, L2 규제입니다.
리지 회귀는 linear_model.Ridge 에 구현되어있습니다.
✏️ 보스턴 주택 가격을 선형 회귀로 분석
from sklearn.linear_model import LinearRegression
X, y = mglearn.datasets.load_extended_boston()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
lr = LinearRegression().fit(X_train, y_train)
print("훈련 세트 점수: {:.2f}".format(lr.score(X_train, y_train)))
print("테스트 세트 점수: {:.2f}".format(lr.score(X_test, y_test)))
✏️ 보스턴 주택 가격을 리지 회귀로 분석
from sklearn.linear_model import Ridge
ridge = Ridge().fit(X_train, y_train)
print("훈련 세트 점수: {:.2f}".format(ridge.score(X_train, y_train)))
print("테스트 세트 점수: {:.2f}".format(ridge.score(X_test, y_test)))
선형 회귀로 분석했을 때 훈련 세트 점수는 0.95가 나오고 테스트 세트 점수는 0.61이 나옵니다. 하지만 리지 회귀로 분석했을 때는 훈련 세트 점수 0.89, 테스트 세트 점수 0.75입니다. 이것이 뜻하는 바가 무엇일까요?
바로 선형 회귀로 분석했을 때는 과대적합이 일어나고 리지 회귀로 분석했을 때는 규제로 인해서 과대적합이 줄어들었다고 해석할 수 있습니다. 모델의 복잡도가 낮아지면 단편적으로 훈련 세트에서의 성능이 떨어진다 생각할 수 있겠지만, 더 일반적인 모델을 모델링할 수 있다는 장점이 있습니다.
2. alpha 매개변수
리지 회귀는 alpha 매개변수를 가집니다. alpha 매개변수란, 훈련 세트의 성능 대비 모델을 얼마나 단순화할지 지정할 수 매개변수입니다.
이는 기본적으로 1 로 세팅 되어 있지만, 이 값이 절대적인 것이 아닙니다. 즉, 최적의 alpha의 값을 우리가 찾아야 하는 것이죠. alpha의 값이 0에 가까워질수록 훈련 세트의 성능은 나빠지기 마련입니다. 계수에 대한 제약이 풀리는 것이기 때문인데요, 이 말이 조금 어려울 수 있습니다. 저는 이를 처리할 특성이 줄어들었다! 로 이해하였습니다.
여기서 주의해야 할 점은 아주 작은 alpha값은 계수를 거의 제한하지 않는 것과 같기 대문에 선형 회귀의 모델과 유사합니다. 즉 alpha값을 0에 가깝게 할 것이라면 굳이 리지 회귀를 쓸 필요가 없다는 것이죠.
라소
Lasso
1. 라소란?
라소는 리지의 대안이라고 볼 수 있습니다. 이역시 계수를 0에 가깝게 만들려고 합니다. 하지만 방식이 조금 달라 이를 L1 규제 라고 합니다.
자, 여기서 L2와의 차이점이 있는데요, 바로 L1 규제는 계수를 0에 가깝게 만들다가 어떤 계수들이 정말 0이 됩니다. 즉 완전히 제외되는 특성이 생긴다는 것입니다. 이는 모델에 대한 이해도를 높일 수 있다는 장점이 있습니다.
라소는 linear_model.Lasso 에 구현되어있습니다.
2. alpha 매개변수
라소에서 alpha 매개변수는 과소적합을 줄이기 위한 것입니다. 이것이 리지와는 다르죠. 리지는 과대적합을 줄이기 위해서였으니까요.
라소에서 alpha 매개변수는 사용할 때는 max_iter(max iteration)의 기본값을 늘려야 하는데, 이는 반복을 실행하는 최대 횟수입니다, alpha 값을 낮추면 모델의 복잡도는 증가합니다.
모델의 복잡도 증가는 처리할 특성이 많아진다 는 뜻이라 생각하면 이해하기 쉽습니다.
분류용 선형 모델
ŷ = w[0] × x[0] + w[1] × x[1] + … + w[p] × x[p] > b
이진 분류에서는 예측값과 임계치 0을 비교하게 됩니다. 예측값이 0보다 작다면 클래스는 -1, 0보다 크다면 1이 됩니다.
이 모델에서는 결정 경계가 입력의 선형 함수입니다. 즉 선, 평면, 초평면이 클래스를 분류하는 기준이 된다는 것이죠.
선형 모델을 학습시키는 알고리즘은 다양한데, 아래의 두 가지 방법으로 구분할 수 있습니다.
- 특정 계수와 절편의 조합이 훈련 데이터에 얼마나 잘 맞는가?
- 사용할 수 있는 규제가 있다면 어떤 방식인가?
가장 널리 알려진 두 개의 선형 분류 알고리즘은 로지스틱 회귀와 서포트 벡터 머신입니다. 로지스틱 회귀에 회귀라는 말이 들어가지만 회귀 알고리즘이 아니라 분류 알고리즘이라는 것을 기억해야 합니다!
두 알고리즘은 L2 규제 를 사용합니다. 여기에서도 규제의 강도를 결정하는 매개변수가 존재하는데, 바로 C 입니다. C의 값이 높아지면 규제가 감소합니다.
즉, 알고리즘은 c의 값이 낮아지면 데이터 포인트 중 다수에 맞추려고 하지만, c의 값을 높이면 개개의 데이터 포인트를 정확히 분류하려고 노력할 것입니다. c 값을 높인다는 것은 규제를 감소시킨다는 것이므로 이 말은 overfitting의 정도를 높인다고 할 수 있겠죠?
다중 클래스 분류용 선형 모델
로지스틱 회귀를 제외한 선형 분류 모델은 이진 분류만을 지원합니다.
그래서 다중 클래스를 분류할 때에는 일대다 방법 을 사용합니다. 이 방식은 각 클래스를 다른 모든 클래스와 구분하도록 이진 분류 모델을 학습하는 것입니다. 결국 클래스의 수만큼 이진 분류 모델이 만들어지며 예측을 할 때 이렇게 만들어진 모든 이진 분류기가 작동하여 가장 높은 점수를 내는 분류기의 클래스를 예측값으로 선택합니다.

왼쪽의 그래프의 경계를 시각화한 것이 바로 오른쪽 그래프입니다. 기본적으로 새로운 데이터에 대해 판단할 때는 경계값, 여기서는 각각의 직선이겠죠? 이를 기준으로 클래스 0, 1을 판단합니다.
하지만 만약 경계의 교집합인 삼각형에 데이터가 포함된다면 어떻게 할까요? 바로 가장 가까운 직선의 클래스가 됩니다.
선형 모델 정리
앞서 공부한 내용들을 지금부터 요약해보겠습니다.
- 선형 모델의 주요 매개변수
- 회귀모델: alpha
- 로지스틱 회귀/서포트 벡터 머신: C
-
alpha의 값이 커지거나 C의 값이 작아지는 것은 규제를 강하게 하는 것임: 이 말은 모델을 더욱 단순히 만들 수 있다는 뜻이기에 과대적합을 줄일 수 있습니다.
-
규제의 종류
- L1 규제: 중요한 특성이 많다고 생각할 때 사용해야 합니다.
- L2 규제: 기본적으로는 L2 규제를 사용합니다.
-
선형 모델은 학습의 속도가 빠르고 예측 역시 빠릅니다.
-
회귀와 분류의 공식을 사용해 예측이 어떻게 만들어지는지 비교적 쉽게 이해할 수 있습니다.
-
샘플에 비해 특성이 많을 때 사용한다면 잘 작동합니다.
나이브 베이즈 분류기
드디어 마지막! 나이브 베이즈 분류기입니다.
이는 선형 모델과 매우 유사한데 다른 선형 분류기보다 훈련 속도가 훨 빠르지만 일반화 성능이 뒤쳐진다는 단점이 있습니다.
나이브 베이즈 분류기가 유용한 이유는 각 특성을 개별로 취급해서 파라미터를 학습하고 각 특성에서 클래스별 통계를 단순하게 취급한다는 것입니다.
나이브 베이즈 분류기는 다음과 같이 나뉩니다.
- GaussianNB: 연속적 데이터
- BernoulliNB: 이진 데이터
- MultinomialNB: 카운트 데이터
여기서 BernoulliNB와 MultinomialNB는 대부분 텍스트 데이터를 분류할 때 사용합니다. 또 GaussianNB와 MultinomialNB는 계산하는 통계 데이터의 종류가 조금 다릅니다. MultinomialNB는 클래스별로 특성의 평균을 계산하고 GaussianNB는 클래스별로 각 특성의 표준편차와 평균을 저장합니다.
여기까지가 3주차의 지도학습 내용입니다. 내용이 낯설어 어렵게 느껴지셨으리라 생각합니다. 하지만 지금까지 설명한 것은 모두 머신러닝에서 자주 쓰이는 모델들이기 때문에, 잘 숙지하고 있어 주시길 바랍니다! 😀👏
